13- 法定人对象QuorumPeer启动之加载磁盘快照与事务日志
13.1 简介
前面我们了解了管理协议的法定人对象QuorumPeer的启动方法如下
//重写了线程的start方法 start为代理方法在启动之前做一些逻辑处理
quorumPeer.start();在QuorumPeer类型中 重写了start方法,启动线程的调用被放在了start方法的最后,启动之前,这种代理方法策略一般用于我们对某些操作逻辑的增强逻辑类似AOP机制 , start操作如下代码:
@Override
public synchronized void start() {
//getView是当前初始化的法定人对象 列表
if (!getView().containsKey(myid)) {
throw new RuntimeException("My id " + myid + " not in the peer list");
}
//将数据从磁盘加载到内存中,并将事务添加到内存中的committedlog中。 读取快照和事物文件
loadDataBase();
//服务端开启连接线程
startServerCnxnFactory();
try {
//开启管理端
adminServer.start();
} catch (AdminServerException e) {
LOG.warn("Problem starting AdminServer", e);
System.out.println(e);
}
//开启选举功能
startLeaderElection();
//开启JVM监控
startJvmPauseMonitor();
//线程启动QuorumPeer开始运行
super.start();
}关于事务日志的加载 其实包含了两部分,
- 一部分是Zookeper定期将事务日志压缩的快照
- 一部分是还未压缩的事务增量数据
Zookeeper通过这样的机制保证数据空间的压缩与可靠性保证
12.3 恢复本地数据到内存的模板方法
在法定人线程启动之前先执行了 恢复本地数据到内存
loadDataBase();这个方法是将数据库从磁盘加载到内存中,并将事务添加到内存中的committedlog中。最后返回磁盘上最后一个有效的zxid
ZKDatabase功能:ZKDatabase负责管理会话、DataTree和事务日志,向上层提供统一的数据操作接口,其基本结构如下图所示
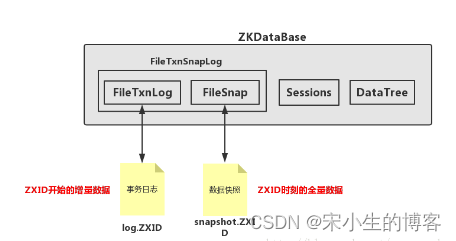
也就是说Zookeeper在处理事务的时候会将事务持久化到磁盘里面等到,关闭进程重启的时候会加载这些事务信息可以保证数据不丢失。
接下来让我们学习下zookeeper是如何将磁盘中的数据库快照同步到内存的:
QuorumPeer类型中
private void loadDataBase() {
try {
//加载数据库到内存核心代码,这个zkDb是ZKDatabase对象 ZKDatabase是quorumpeer的顶级成员,将在稍后实例化的所有Zookeeperserver中使用。此外,它在引导时创建一次,只有在引导者发出截断消息时才会丢弃
zkDb.loadDataBase();
// load the epochs
//最新的处理事物id,在处理事物的时候处理完成的事物会将最新事物id更新到lastProcessedZxid,在处理事物时候有个zxid这里是不能直接用的会读取到脏数据
//当我们修改数据树时,快照可能正在进行中。如果我们在对树进行相应更改之前设置lastProcessedZxid,那么与快照文件关联的zxid将位于其内容之前。因此,在从快照进行恢复时,恢复方法将不会应用事务
//对于与快照文件关联的zxid,因为恢复方法假定快照中存在该事务。为了避免这种情况,我们首先应用事务,然后修改lastProcessedZxid。在恢复期间,我们正确地处理了快照包含zxid之前的数据的情况
与文件
long lastProcessedZxid = zkDb.getDataTree().lastProcessedZxid;
//为了保证事务的顺序一致性,zookeeper采用了递增的事务id号(zxid)来标识事务。所有的提议(proposal)都在被提出的时候加上了zxid。实现中zxid是一个64位的数字,它高32位是epoch用来标识 leader关系是否改变,每次一个leader被选出来,它都会有一个新的epoch,标识当前属于那个leader的统治时期。低32位用于递增计数。
//epoch:可以理解为当前集群所处的年代或者周期,每个leader就像皇帝,都有自己的年号,所以每次改朝换代,leader变更之后,都会在前一个年代的基础上加1。这样就算旧的leader崩溃恢复之后,也没有人听他的了,因为follower只听从当前年代的leader的命令
//在这里呢就是获取高32位用来标示leader关系是否改变的值 ZxidUtils zxid工具类
long epochOfZxid = ZxidUtils.getEpochFromZxid(lastProcessedZxid);
try {
//接下来就是读取数据文件目录中的currentEpoch文件,文件中显示的是当前的epoch。 只有一个数字
//其实程序中还有个epoch文件
//acceptedEpoch:没有确认的epoch,LEADERINFO阶段
//currentEpoch:确认的epoch,接收到UPTODATE后
currentEpoch = readLongFromFile(CURRENT_EPOCH_FILENAME);
//如果从快照文件中读取的epoch id大于currentEpoch文件中的id号则将快照中读取的最新的epoch号更新到文件currentEpoch文件中
if (epochOfZxid > currentEpoch && updating.exists()) {
LOG.info("{} found. The server was terminated after " +
"taking a snapshot but before updating current " +
"epoch. Setting current epoch to {}.",
UPDATING_EPOCH_FILENAME, epochOfZxid);
setCurrentEpoch(epochOfZxid);
if (!updating.delete()) {
throw new IOException("Failed to delete " +
updating.toString());
}
}
} catch(FileNotFoundException e) {
//...
} catch(IOException ie) {
//...
}
}这个模板方法我们总结一下:
- 使用ZKDatabase加载事务快照日志和事务增量日志
- 数据恢复完成后从ZKDatabase查询最新的最新的处理事物id lastProcessedZxid
- 获取高32位用来标示leader关系是否改变的值epochOfZxid
- 读取数据文件目录中的currentEpoch文件,文件中显示的是当前的epoch
- 刷新内存中的epoch值,继续上个纪元开始,不能从0开始
13.3 Zookeeper数据库管理加载磁盘快照的核心方法
接下来我们就重点看下zookeeper如何把磁盘中的数据加载到内存中
ZKDatabase类型中的加载方法:
这个zkDb是ZKDatabase对象 ZKDatabase是quorumpeer的顶级成员,将在稍后实例化的所有Zookeeperserver中使用。此外,它在引导时创建一次,只有在引导者发出截断消息时才会丢弃
public long loadDataBase() throws IOException {
long startTime = Time.currentElapsedTime();
long zxid = snapLog.restore(dataTree, sessionsWithTimeouts, commitProposalPlaybackListener);
initialized = true;
long loadTime = Time.currentElapsedTime() - startTime;
ServerMetrics.getMetrics().DB_INIT_TIME.add(loadTime);
LOG.info("Snapshot loaded in {} ms, highest zxid is 0x{}, digest is {}",
loadTime, Long.toHexString(zxid), dataTree.getTreeDigest());
return zxid;
}这里比简单 这个方法其实是个代理方法 本来执行snapLog.restore 增加一个loadDataBase()在事务日志执行前后加了埋点这样就可以看到数据库文件初始化加载的耗时
13.3.1 事务快照日志的恢复过程
再来看FileTxnSnapLog中的restore方法:
下面只有两个位置需要看 用!!! 提示了
- 反序列化过程 !!! 第一个要看的位置
long deserializeResult = snapLog.deserialize(dt, sessions); - 恢复事物日志 !!! 第二个要看的位置 fastForwardFromEdits
long highestZxid = fastForwardFromEdits(dt, sessions, listener);public long restore(DataTree dt, Map<Long, Integer> sessions, PlayBackListener listener) throws IOException { long snapLoadingStartTime = Time.currentElapsedTime(); //反序列化过程 !!! 第一个要看的位置 long deserializeResult = snapLog.deserialize(dt, sessions); ServerMetrics.getMetrics().STARTUP_SNAP_LOAD_TIME.add(Time.currentElapsedTime() - snapLoadingStartTime); FileTxnLog txnLog = new FileTxnLog(dataDir); boolean trustEmptyDB; File initFile = new File(dataDir.getParent(), "initialize"); if (Files.deleteIfExists(initFile.toPath())) { LOG.info("Initialize file found, an empty database will not block voting participation"); trustEmptyDB = true; } else { trustEmptyDB = autoCreateDB; } //恢复事物日志 !!! 第二个要看的位置 fastForwardFromEdits RestoreFinalizer finalizer = () -> { long highestZxid = fastForwardFromEdits(dt, sessions, listener); // The snapshotZxidDigest will reset after replaying the txn of the // zxid in the snapshotZxidDigest, if it's not reset to null after // restoring, it means either there are not enough txns to cover that // zxid or that txn is missing DataTree.ZxidDigest snapshotZxidDigest = dt.getDigestFromLoadedSnapshot(); if (snapshotZxidDigest != null) { LOG.warn( "Highest txn zxid 0x{} is not covering the snapshot digest zxid 0x{}, " + "which might lead to inconsistent state", Long.toHexString(highestZxid), Long.toHexString(snapshotZxidDigest.getZxid())); } return highestZxid; }; //这里是快照日志为空 if (-1L == deserializeResult) { /* this means that we couldn't find any snapshot, so we need to * initialize an empty database (reported in ZOOKEEPER-2325) */ //这里判断事物日志不为空 if (txnLog.getLastLoggedZxid() != -1) { // ZOOKEEPER-3056: provides an escape hatch for users upgrading // from old versions of zookeeper (3.4.x, pre 3.5.3). if (!trustEmptySnapshot) { throw new IOException(EMPTY_SNAPSHOT_WARNING + "Something is broken!"); } else { LOG.warn("{}This should only be allowed during upgrading.", EMPTY_SNAPSHOT_WARNING); return finalizer.run(); } } if (trustEmptyDB) { /* TODO: (br33d) we should either put a ConcurrentHashMap on restore() * or use Map on save() */ save(dt, (ConcurrentHashMap<Long, Integer>) sessions, false); /* return a zxid of 0, since we know the database is empty */ return 0L; } else { /* return a zxid of -1, since we are possibly missing data */ LOG.warn("Unexpected empty data tree, setting zxid to -1"); dt.lastProcessedZxid = -1L; return -1L; } } //执行事物日志恢复 return finalizer.run(); }
上面我们主要看两个点就行了
- 反序列化过程 !!! 第一个要看的位置
long deserializeResult = snapLog.deserialize(dt, sessions); - 恢复事物日志 !!! 第二个要看的位置 fastForwardFromEdits
long highestZxid = fastForwardFromEdits(dt, sessions, listener);
13.3.2 反序列化事务快照日志的过程
再来看FileSnap中的序列化事物方法 降序查询最新的100个快照依次遍历找到第一个合法的快照文件并将其恢复,最后返回当前恢复的最新的快照对应的事物id:
下面主要看两个位置:
- 查询最近的具有snapshot前缀的100个快照文件,
List<File> snapList = findNValidSnapshots(100); - 反序列化文件到内存
deserialize(dt, sessions, ia);public long deserialize(DataTree dt, Map<Long, Integer> sessions) throws IOException {
// we run through 100 snapshots (not all of them)
// if we cannot get it running within 100 snapshots
// we should give up
//查询最近的具有snapshot前缀的100个快照文件,
List<File> snapList = findNValidSnapshots(100);
if (snapList.size() == 0) {
return -1L;
}
File snap = null;
long snapZxid = -1;
boolean foundValid = false;
//遍历这些文件 对数据流进行Adler-32数据校验
for (int i = 0, snapListSize = snapList.size(); i < snapListSize; i++) {
snap = snapList.get(i);
LOG.info("Reading snapshot {}", snap);
snapZxid = Util.getZxidFromName(snap.getName(), SNAPSHOT_FILE_PREFIX);
try (CheckedInputStream snapIS = SnapStream.getInputStream(snap)) {
InputArchive ia = BinaryInputArchive.getArchive(snapIS);
//反序列化的过程就是把磁盘快照中的数据这些快照数据使用了数据流来操作DataInputStream,反序列化的时候调用DataTree类型的deserialize方法来将数据流读取出来读入DataTree对象中,所以说DataTree是相当于快照数据的内存映射
deserialize(dt, sessions, ia);
SnapStream.checkSealIntegrity(snapIS, ia);
// Digest feature was added after the CRC to make it backward
// compatible, the older code can still read snapshots which
// includes digest.
//
// To check the intact, after adding digest we added another
// CRC check.
if (dt.deserializeZxidDigest(ia, snapZxid)) {
SnapStream.checkSealIntegrity(snapIS, ia);
}
foundValid = true;
break;
} catch (IOException e) {
LOG.warn("problem reading snap file {}", snap, e);
}
}
if (!foundValid) {
throw new IOException("Not able to find valid snapshots in " + snapDir);
}
dt.lastProcessedZxid = snapZxid;
lastSnapshotInfo = new SnapshotInfo(dt.lastProcessedZxid, snap.lastModified() / 1000);
// compare the digest if this is not a fuzzy snapshot, we want to compare
// and find inconsistent asap.
if (dt.getDigestFromLoadedSnapshot() != null) {
dt.compareSnapshotDigests(dt.lastProcessedZxid);
}
return dt.lastProcessedZxid;
}
//反序列化模板方法
public void deserialize(DataTree dt, Map<Long, Integer> sessions, InputArchive ia) throws IOException {
//使用jute读取文件头,进行校验
FileHeader header = new FileHeader();
header.deserialize(ia, "fileheader");
if (header.getMagic() != SNAP_MAGIC) {
throw new IOException("mismatching magic headers " + header.getMagic() + " != " + FileSnap.SNAP_MAGIC);
}
//反序列化快照文件
SerializeUtils.deserializeSnapshot(dt, ia, sessions);
}这个FileHeader是zookeeper下jute模块的序列化组建
这里主要看下SerializeUtils.deserializeSnapshot(dt, ia, sessions);
SerializeUtils类型下的快照序列化方法:
public static void deserializeSnapshot(DataTree dt, InputArchive ia, Map<Long, Integer> sessions) throws IOException {
int count = ia.readInt("count");
while (count > 0) {
long id = ia.readLong("id");
int to = ia.readInt("timeout");
sessions.put(id, to);
if (LOG.isTraceEnabled()) {
ZooTrace.logTraceMessage(
LOG,
ZooTrace.SESSION_TRACE_MASK,
"loadData --- session in archive: " + id + " with timeout: " + to);
}
count--;
}
//反序列化DataTree
dt.deserialize(ia, "tree");
}最后调用DataTree的反序列化方法deserialize:
public void deserialize(InputArchive ia, String tag) throws IOException {
//反序列化acl数据
aclCache.deserialize(ia);
nodes.clear();
pTrie.clear();
nodeDataSize.set(0);
String path = ia.readString("path");
//下面是反序列化节点数据
while (!"/".equals(path)) {
DataNode node = new DataNode();
ia.readRecord(node, "node");
nodes.put(path, node);
synchronized (node) {
aclCache.addUsage(node.acl);
}
int lastSlash = path.lastIndexOf('/');
if (lastSlash == -1) {
root = node;
} else {
String parentPath = path.substring(0, lastSlash);
DataNode parent = nodes.get(parentPath);
if (parent == null) {
throw new IOException("Invalid Datatree, unable to find "
+ "parent "
+ parentPath
+ " of path "
+ path);
}
parent.addChild(path.substring(lastSlash + 1));
long eowner = node.stat.getEphemeralOwner();
EphemeralType ephemeralType = EphemeralType.get(eowner);
if (ephemeralType == EphemeralType.CONTAINER) {
containers.add(path);
} else if (ephemeralType == EphemeralType.TTL) {
ttls.add(path);
} else if (eowner != 0) {
HashSet<String> list = ephemerals.get(eowner);
if (list == null) {
list = new HashSet<String>();
ephemerals.put(eowner, list);
}
list.add(path);
}
}
path = ia.readString("path");
}
// have counted digest for root node with "", ignore here to avoid
// counting twice for root node
nodes.putWithoutDigest("/", root);
nodeDataSize.set(approximateDataSize());
// we are done with deserializing the
// the datatree
// update the quotas - create path trie
// and also update the stat nodes
setupQuota();
aclCache.purgeUnused();
}13.4 事务增量日志加载
在前面 13.3.1 事务快照日志的恢复过程 小节中我们看到事务的快照日志已经加载完毕这是存量的数据,然后还有增量的数据需要加载那就是事务增量的数据我们继续看
从事务日志中恢复数据的实现:fastForwardFromEdits(dt, sessions, listener)
此函数将快速转发服务器数据库,使其具有最新的事务。 这与还原相同,但只从读取事务日志而不是从快照恢复,这个方法主要去读取事物日志数据 先获取到最大事物id,然后直接读取最大事物id对应的事物日志文件,使用TxnIterator迭代器依次遍历事物日志,遍历过程中调用processTransaction去处理事物的session关系,然后调用DataTree类中的processTxn方法来根据具体事物信息来执行对应的CRUD等操作。
public long fastForwardFromEdits(
DataTree dt,
Map<Long, Integer> sessions,
PlayBackListener listener) throws IOException {
//获取比当前快照恢复的最大的事物id更大的那个
TxnIterator itr = txnLog.read(dt.lastProcessedZxid + 1);
long highestZxid = dt.lastProcessedZxid;
TxnHeader hdr;
int txnLoaded = 0;
long startTime = Time.currentElapsedTime();
try {
while (true) {
// iterator points to
// the first valid txn when initialized
hdr = itr.getHeader();
if (hdr == null) {
//empty logs
return dt.lastProcessedZxid;
}
//获取当前最大的zxid
if (hdr.getZxid() < highestZxid && highestZxid != 0) {
LOG.error("{}(highestZxid) > {}(next log) for type {}", highestZxid, hdr.getZxid(), hdr.getType());
} else {
highestZxid = hdr.getZxid();
}
try {
//处理事物日志,进行数据恢复,这个处理方法内容就是根据日志内容进行恢复 后续会详细看
processTransaction(hdr, dt, sessions, itr.getTxn());
dt.compareDigest(hdr, itr.getTxn(), itr.getDigest());
txnLoaded++;
} catch (KeeperException.NoNodeException e) {
throw new IOException("Failed to process transaction type: "
+ hdr.getType()
+ " error: "
+ e.getMessage(),
e);
}
//事物日志处理完毕的回调方法
listener.onTxnLoaded(hdr, itr.getTxn(), itr.getDigest());
if (!itr.next()) {
break;
}
}
} finally {
if (itr != null) {
itr.close();
}
}
long loadTime = Time.currentElapsedTime() - startTime;
LOG.info("{} txns loaded in {} ms", txnLoaded, loadTime);
//监控指标数据收集
ServerMetrics.getMetrics().STARTUP_TXNS_LOADED.add(txnLoaded);
ServerMetrics.getMetrics().STARTUP_TXNS_LOAD_TIME.add(loadTime);
return highestZxid;
}事务日志主要看下
//txnLog是FileTxnLog类型的
TxnIterator itr = txnLog.read(dt.lastProcessedZxid + 1);
这个FileTxnLog的read方法就不展开了其实就是读取文件的一个方法
以上就是zookeeper中loadDataBase恢复数据的过程,恢复过程采用了快照数据+增量事物日志数据恢复的思想来完整恢复关闭之前的全量数据。
查看原文,技术咨询与支持,可以扫描微信公众号进行回复咨询
Zookeeper16, Zookeeper安装配置14, Zookeeper源码解析16