16-QuorumPeer主循环
16.1 主循环简介
QuorumPeer 类型是ZookeeperThread的子类型是一个线程类型,在QuorumPeer 中通过super.start()方法启动线程
在线程中根据集群的状态来决定是否需要参与投票,加入集群
这里先贴一下线程运行的完整代码:
@Override
public void run() {
//设置当前线程名称
updateThreadName();
LOG.debug("Starting quorum peer");
try {
//注册jmxBean
jmxQuorumBean = new QuorumBean(this);
MBeanRegistry.getInstance().register(jmxQuorumBean, null);
for (QuorumServer s : getView().values()) {
ZKMBeanInfo p;
if (getId() == s.id) {
p = jmxLocalPeerBean = new LocalPeerBean(this);
try {
MBeanRegistry.getInstance().register(p, jmxQuorumBean);
} catch (Exception e) {
LOG.warn("Failed to register with JMX", e);
jmxLocalPeerBean = null;
}
} else {
RemotePeerBean rBean = new RemotePeerBean(this, s);
try {
MBeanRegistry.getInstance().register(rBean, jmxQuorumBean);
jmxRemotePeerBean.put(s.id, rBean);
} catch (Exception e) {
LOG.warn("Failed to register with JMX", e);
}
}
}
} catch (Exception e) {
LOG.warn("Failed to register with JMX", e);
jmxQuorumBean = null;
}
try {
/*
* Main loop
*/
while (running) {
//当前服务器一共有四种状态LOOKING,FOLLOWING,LEADING,OBSERVING
switch (getPeerState()) {
case LOOKING:
LOG.info("LOOKING");
ServerMetrics.getMetrics().LOOKING_COUNT.add(1);
if (Boolean.getBoolean("readonlymode.enabled")) {
LOG.info("Attempting to start ReadOnlyZooKeeperServer");
// Create read-only server but don't start it immediately
final ReadOnlyZooKeeperServer roZk = new ReadOnlyZooKeeperServer(logFactory, this, this.zkDb);
// Instead of starting roZk immediately, wait some grace
// period before we decide we're partitioned.
//
// Thread is used here because otherwise it would require
// changes in each of election strategy classes which is
// unnecessary code coupling.
Thread roZkMgr = new Thread() {
public void run() {
try {
// lower-bound grace period to 2 secs
sleep(Math.max(2000, tickTime));
if (ServerState.LOOKING.equals(getPeerState())) {
roZk.startup();
}
} catch (InterruptedException e) {
LOG.info("Interrupted while attempting to start ReadOnlyZooKeeperServer, not started");
} catch (Exception e) {
LOG.error("FAILED to start ReadOnlyZooKeeperServer", e);
}
}
};
try {
roZkMgr.start();
reconfigFlagClear();
if (shuttingDownLE) {
shuttingDownLE = false;
startLeaderElection();
}
setCurrentVote(makeLEStrategy().lookForLeader());
} catch (Exception e) {
LOG.warn("Unexpected exception", e);
setPeerState(ServerState.LOOKING);
} finally {
// If the thread is in the the grace period, interrupt
// to come out of waiting.
roZkMgr.interrupt();
roZk.shutdown();
}
} else {
try {
reconfigFlagClear();
//是否需要重新创建新的投票对象,重新创建选举算法
if (shuttingDownLE) {
shuttingDownLE = false;
startLeaderElection();
}
先看lookForLeader方法:开始新一轮的leader选举。每当我们的 QuorumPeer 将其状态更改为 LOOKING 时,就会调用此方法,并向所有其他对等方发送通知。
setCurrentVote为当前投票结果
setCurrentVote(makeLEStrategy().lookForLeader());
} catch (Exception e) {
LOG.warn("Unexpected exception", e);
setPeerState(ServerState.LOOKING);
}
}
break;
case OBSERVING:
try {
LOG.info("OBSERVING");
setObserver(makeObserver(logFactory));
observer.observeLeader();
} catch (Exception e) {
LOG.warn("Unexpected exception", e);
} finally {
observer.shutdown();
setObserver(null);
updateServerState();
// Add delay jitter before we switch to LOOKING
// state to reduce the load of ObserverMaster
if (isRunning()) {
Observer.waitForObserverElectionDelay();
}
}
break;
case FOLLOWING:
try {
LOG.info("FOLLOWING");
setFollower(makeFollower(logFactory));
follower.followLeader();
} catch (Exception e) {
LOG.warn("Unexpected exception", e);
} finally {
follower.shutdown();
setFollower(null);
updateServerState();
}
break;
case LEADING:
LOG.info("LEADING");
try {
setLeader(makeLeader(logFactory));
leader.lead();
setLeader(null);
} catch (Exception e) {
LOG.warn("Unexpected exception", e);
} finally {
if (leader != null) {
leader.shutdown("Forcing shutdown");
setLeader(null);
}
updateServerState();
}
break;
}
}
} finally {
LOG.warn("QuorumPeer main thread exited");
MBeanRegistry instance = MBeanRegistry.getInstance();
instance.unregister(jmxQuorumBean);
instance.unregister(jmxLocalPeerBean);
for (RemotePeerBean remotePeerBean : jmxRemotePeerBean.values()) {
instance.unregister(remotePeerBean);
}
jmxQuorumBean = null;
jmxLocalPeerBean = null;
jmxRemotePeerBean = null;
}
}集群节点状态 QuorumPeer#ServerState 枚举
// 寻找leader状态。当服务器处于该状态时,它会认为当- 前集群中没有leader,因此需要进入leader选举状态。
- LOOKING,
// 跟随者状态。表明当前服务器角色是 follower。 - FOLLOWING,
// 领导者状态。表明当前服务器角色是 leader。 - LEADING,
// 观察者状态。表明当前服务器角色是 observer。 - OBSERVING
16.2 LOOKING状态逻辑
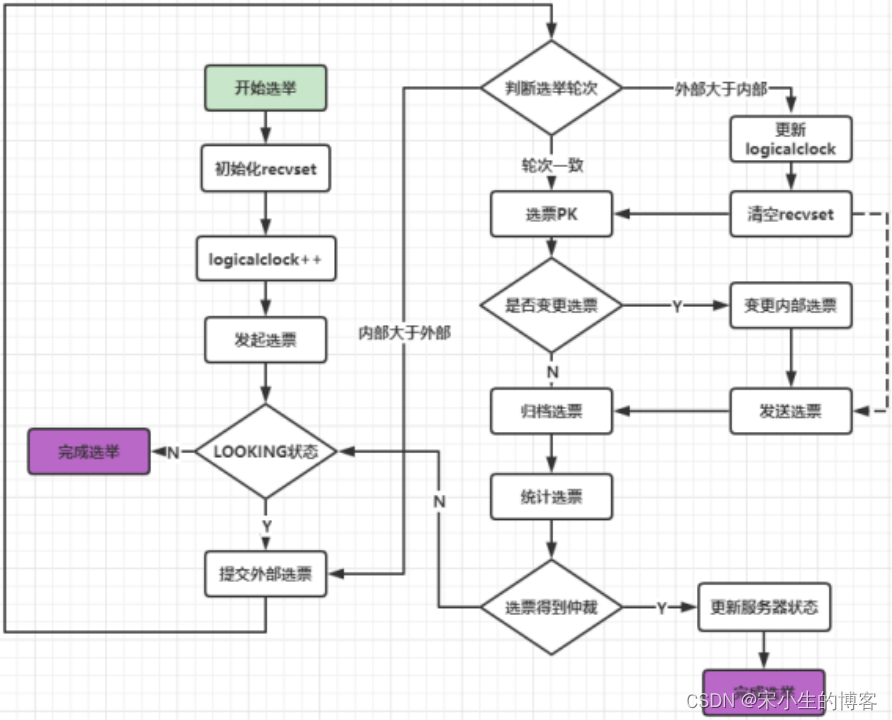
当处于LOOKING状态时我们看下核心逻辑:
startLeaderElection();
开始选举我们前面了解过在启动QuorumPeer之前就执行过一次创建选举算法和启动选举交互线程
再继续看发起投票代码:
setCurrentVote(makeLEStrategy().lookForLeader());
获取投票策略makeLEStrategy这个就是我们前面创建的FastLeaderElection对象
接下来看下lookForLeader选主过程:
选主投票原文:
https://www.cnblogs.com/wuzhenzhao/p/9983231.html
public Vote lookForLeader() throws InterruptedException {
try {
//注册MBean
self.jmxLeaderElectionBean = new LeaderElectionBean();
MBeanRegistry.getInstance().register(self.jmxLeaderElectionBean, self.jmxLocalPeerBean);
} catch (Exception e) {
LOG.warn("Failed to register with JMX", e);
self.jmxLeaderElectionBean = null;
}
self.start_fle = Time.currentElapsedTime();
try {
/*
* The votes from the current leader election are stored in recvset. In other words, a vote v is in recvset
* if v.electionEpoch == logicalclock. The current participant uses recvset to deduce on whether a majority
* of participants has voted for it.
当前领导人选举的选票存储在 recvset 中。换句话说,如果 v.electionEpoch == logicalclock,则投票 v 在 recvset 中。当前参与者使用 recvset 来推断是否大多数参与者都投票支持它。
*/
//收到的投票
Map<Long, Vote> recvset = new HashMap<Long, Vote>();
/*
* The votes from previous leader elections, as well as the votes from the current leader election are
* stored in outofelection. Note that notifications in a LOOKING state are not stored in outofelection.
* Only FOLLOWING or LEADING notifications are stored in outofelection. The current participant could use
* outofelection to learn which participant is the leader if it arrives late (i.e., higher logicalclock than
* the electionEpoch of the received notifications) in a leader election.
之前领导人选举的选票,以及当前领导人选举的选票都存储在 outofelection 中。请注意,处于 LOOKING 状态的通知不会存储在 outofelection 中。只有 FOLLOWING 或 LEADING 通知存储在 outofelection 中。当前参与者可以使用 outofelection 来了解如果它迟到(即比逻辑时钟更高的逻辑时钟)哪个参与者是领导者 收到通知的选举纪元)在领导选举中。
*/
//存储选举结果
Map<Long, Vote> outofelection = new HashMap<Long, Vote>();
int notTimeout = minNotificationInterval;
synchronized (this) {
//更新逻辑时钟,用来判断是否在同一轮选举周期
logicalclock.incrementAndGet();
//初始化选票数据:这里其实就是把当前节点的myid,zxid,epoch更新到本地的成员属性
updateProposal(getInitId(), getInitLastLoggedZxid(), getPeerEpoch());
}
LOG.info(
"New election. My id = {}, proposed zxid=0x{}",
self.getId(),
Long.toHexString(proposedZxid));
//异步发送选举消息 先投自己一票
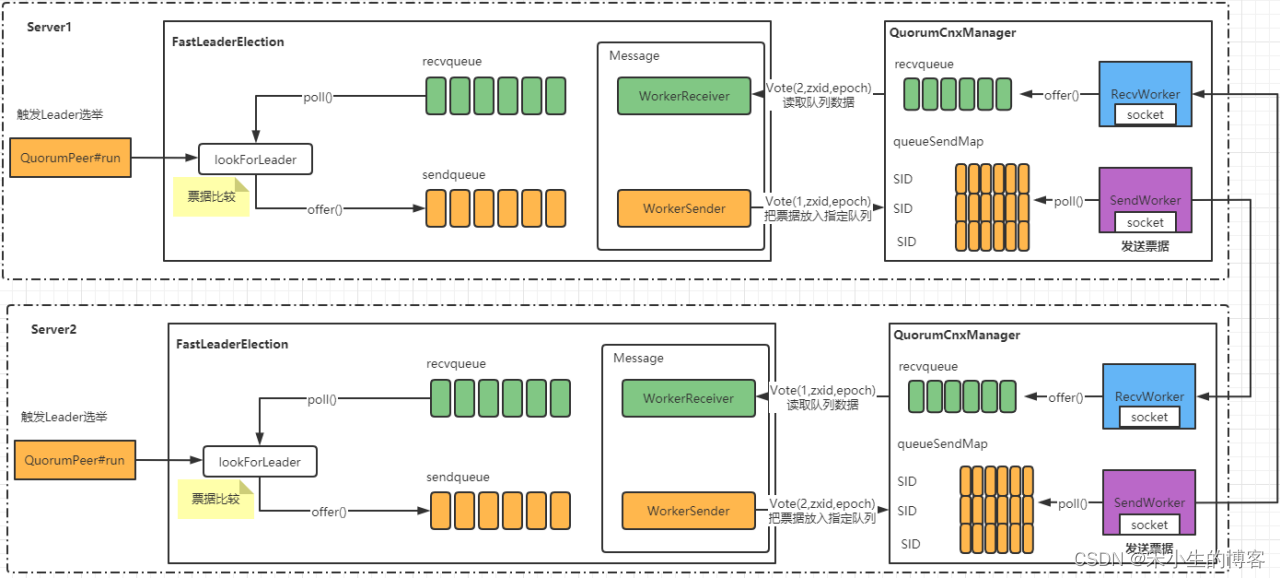
sendNotifications();
SyncedLearnerTracker voteSet;
/*
* Loop in which we exchange notifications until we find a leader
*/
//不断循环,根据投票信息进行leader选举
while ((self.getPeerState() == ServerState.LOOKING) && (!stop)) {
/*
* Remove next notification from queue, times out after 2 times
* the termination time
*/
//从recvqueue中获取消息,也就是说recvqueue中存储了集群中其他节点的投票信息
Notification n = recvqueue.poll(notTimeout, TimeUnit.MILLISECONDS);
/*
* Sends more notifications if haven't received enough.
* Otherwise processes new notification.
*/
// 如果没有获取到足够的通知久一直发送自己的选票,也就是持续进行选举
if (n == null) {
if (manager.haveDelivered()) {
//判断发送队列是否有数据,如果发送队列为空,再发一次自己的选票
sendNotifications();
} else {
// 消息没发出去,可能其他集群没启动 继续尝试连接
manager.connectAll();
}
/*
* Exponential backoff
*/
// 延长超时时间
int tmpTimeOut = notTimeout * 2;
notTimeout = Math.min(tmpTimeOut, maxNotificationInterval);
LOG.info("Notification time out: {} ms", notTimeout);
// 收到投票消息 查看是否属于本集群内的消息
} else if (validVoter(n.sid) && validVoter(n.leader)) {
/*
* Only proceed if the vote comes from a replica in the current or next
* voting view for a replica in the current or next voting view.
*/
//判断接收到的投票者的状态,默认是LOOKING状态,说明当前发起投票的服务器也是在找leader
switch (n.state) {
case LOOKING:
//忽略zxid=-1的通知
if (getInitLastLoggedZxid() == -1) {
LOG.debug("Ignoring notification as our zxid is -1");
break;
}
if (n.zxid == -1) {
LOG.debug("Ignoring notification from member with -1 zxid {}", n.sid);
break;
}
// If notification > current, replace and send messages out
// 如果收到的投票的逻辑时钟大于当前的节点的逻辑时钟,那么会更新本机的logicallock
// 判断epoch 是否大于 logicalclock ,如是,则是新一轮选举
if (n.electionEpoch > logicalclock.get()) {
// 更新本地logicalclock
logicalclock.set(n.electionEpoch);
// 清空接受队列
recvset.clear();
//接收到的投票和当前节点的信息进行比较,比较的顺序epoch、zxid、myid,如果返 回true,则更新当前节点的票据(sid,zxid,epoch),那么下次再发起投票的时候,就不再是选自己了
if (totalOrderPredicate(n.leader, n.zxid, n.peerEpoch, getInitId(), getInitLastLoggedZxid(), getPeerEpoch())) {
updateProposal(n.leader, n.zxid, n.peerEpoch);
} else {
//否则,表示自己的票据是最新的,则更新自己的票据
updateProposal(getInitId(), getInitLastLoggedZxid(), getPeerEpoch());
}
// 继续广播票据,让其他节点知道我现在的投票
sendNotifications();
} else if (n.electionEpoch < logicalclock.get()) {
//如果是epoch小于当前 忽略
LOG.debug(
"Notification election epoch is smaller than logicalclock. n.electionEpoch = 0x{}, logicalclock=0x{}",
Long.toHexString(n.electionEpoch),
Long.toHexString(logicalclock.get()));
break;
} else if (totalOrderPredicate(n.leader, n.zxid, n.peerEpoch, proposedLeader, proposedZxid, proposedEpoch)) {
//这个判断表示收到的票据的epoch是相同的,那么按照epoch、zxid、myid顺序进 行比较比较成功以后,把对方的票据信息更新到自己的节点
updateProposal(n.leader, n.zxid, n.peerEpoch);
sendNotifications();
}
LOG.debug(
"Adding vote: from={}, proposed leader={}, proposed zxid=0x{}, proposed election epoch=0x{}",
n.sid,
n.leader,
Long.toHexString(n.zxid),
Long.toHexString(n.electionEpoch));
// don't care about the version if it's in LOOKING state
//将收到的投票信息放入投票的集合 recvset 中, 用来作为最终的 "过半原则" 判断
recvset.put(n.sid, new Vote(n.leader, n.zxid, n.electionEpoch, n.peerEpoch));
//获取集群内的所有投票信息 //给定一组投票,返回用于决定是否有足够的凭证宣布选举回合结束。
voteSet = getVoteTracker(recvset, new Vote(proposedLeader, proposedZxid, logicalclock.get(), proposedEpoch));
//是否收到所有的投票确认
if (voteSet.hasAllQuorums()) {
// Verify if there is any change in the proposed leader
// 在超时时间内等待投票
while ((n = recvqueue.poll(finalizeWait, TimeUnit.MILLISECONDS)) != null) {
if (totalOrderPredicate(n.leader, n.zxid, n.peerEpoch, proposedLeader, proposedZxid, proposedEpoch)) {//是否收到所有的投票确认
recvqueue.put(n);
break;
}
}
/*
* This predicate is true once we don't read any new
* relevant message from the reception queue
*///超时时间(200ms)内未收到新的投票,则投票结束
if (n == null) {
//设置当前当前节点的状态(判断leader节点是不是我自己,如果是,直接更新 当前节点的state为LEADING)
//否则,根据当前节点的特性进行判断,决定是FOLLOWING还是OBSE
//判断当前服务在投票结束后 的服务状态
setPeerState(proposedLeader, voteSet);
Vote endVote = new Vote(proposedLeader, proposedZxid, logicalclock.get(), proposedEpoch);
leaveInstance(endVote);
//返回并发送leanding状态的投票
return endVote;
}
}
break;
case OBSERVING:
LOG.debug("Notification from observer: {}", n.sid);
break;
case FOLLOWING:
case LEADING:
/*
* Consider all notifications from the same epoch
* together.
*/
*///如果收到的票据的节点状态已经是LEADING或者FOLLOWING(接收的投票信 息已经有leader选举出了)
//判断收到的票据的epoch和当前节点是否在同一个周期(接收到消息选出了leader跟本 机是在一个选举时代)
if (n.electionEpoch == logicalclock.get()) {
// 判断 epoch 是否相同
recvset.put(n.sid, new Vote(n.leader, n.zxid, n.electionEpoch, n.peerEpoch, n.state));
//获取收到的投票信息,由于判断是否可以结束投票
voteSet = getVoteTracker(recvset, new Vote(n.version, n.leader, n.zxid, n.electionEpoch, n.peerEpoch, n.state));
//判断是否收到所有的投票,并且判断当前节点是否是leader,如果是,则设置状态并返回
if (voteSet.hasAllQuorums() && checkLeader(recvset, n.leader, n.electionEpoch)) {
setPeerState(n.leader, voteSet);
Vote endVote = new Vote(n.leader, n.zxid, n.electionEpoch, n.peerEpoch);
leaveInstance(endVote);
return endVote;
}
}
/*
* Before joining an established ensemble, verify that
* a majority are following the same leader.
*
* Note that the outofelection map also stores votes from the current leader election.
* See ZOOKEEPER-1732 for more information.
*/
//把收到的票据,保存到outofelection集合中
outofelection.put(n.sid, new Vote(n.version, n.leader, n.zxid, n.electionEpoch, n.peerEpoch, n.state));
//收集票据并保存,用来判断投票结束
voteSet = getVoteTracker(outofelection, new Vote(n.version, n.leader, n.zxid, n.electionEpoch, n.peerEpoch, n.state));
//如果为true,则返回leader的投票信息
if (voteSet.hasAllQuorums() && checkLeader(outofelection, n.leader, n.electionEpoch)) {
synchronized (this) {
logicalclock.set(n.electionEpoch);
setPeerState(n.leader, voteSet);
}
Vote endVote = new Vote(n.leader, n.zxid, n.electionEpoch, n.peerEpoch);
leaveInstance(endVote);
return endVote;
}
break;
default:
LOG.warn("Notification state unrecognized: {} (n.state), {}(n.sid)", n.state, n.sid);
break;
}
} else {
if (!validVoter(n.leader)) {
LOG.warn("Ignoring notification for non-cluster member sid {} from sid {}", n.leader, n.sid);
}
if (!validVoter(n.sid)) {
LOG.warn("Ignoring notification for sid {} from non-quorum member sid {}", n.leader, n.sid);
}
}
}
return null;
} finally {
try {
if (self.jmxLeaderElectionBean != null) {
MBeanRegistry.getInstance().unregister(self.jmxLeaderElectionBean);
}
} catch (Exception e) {
LOG.warn("Failed to unregister with JMX", e);
}
self.jmxLeaderElectionBean = null;
LOG.debug("Number of connection processing threads: {}", manager.getConnectionThreadCount());
}
}
protected boolean totalOrderPredicate(long newId, long newZxid, long newEpoch, long curId, long curZxid, long curEpoch) {
LOG.debug("id: " + newId + ", proposed id: " + curId + ", zxid: 0x" +
Long.toHexString(newZxid) + ", proposed zxid: 0x" + Long.toHexString(curZxid));
if(self.getQuorumVerifier().getWeight(newId) == 0){
return false;
}
/*如果以下三种情况之一成立,则返回true:
* 1-选票中epoch更高
* 2-选票中epoch与当前epoch相同,但新zxid更高
* 3-选票中epoch与当前epoch相同,新zxid与当前zxid相同服务器id更高。
*/
//这里判断规则很明显,先比较epoch 如果相等比较 zxid 继续想等继续比较 myid 大的为leader
return ((newEpoch > curEpoch) ||
((newEpoch == curEpoch) &&
((newZxid > curZxid) || ((newZxid == curZxid) && (newId > curId)))));
}
protected boolean termPredicate(HashMap<Long, Vote> votes,Vote vote) {
HashSet<Long> set = new HashSet<Long>();
/*
* First make the views consistent. Sometimes peers will have
* different zxids for a server depending on timing.
*/
// 遍历接收到的集合 把符合当前投票的 放入 Set
for (Map.Entry<Long,Vote> entry : votes.entrySet()) {
if (vote.equals(entry.getValue())){
set.add(entry.getKey());
}
}
// 统计票据,看是否过半
return self.getQuorumVerifier().containsQuorum(set);
}
16.3 OBSERVING状态逻辑
case OBSERVING:
try {
LOG.info("OBSERVING");
//创建observer对象
setObserver(makeObserver(logFactory));
//连接leader
observer.observeLeader();
} catch (Exception e) {
LOG.warn("Unexpected exception", e);
} finally {
observer.shutdown();
setObserver(null);
updateServerState();
// Add delay jitter before we switch to LOOKING
// state to reduce the load of ObserverMaster
if (isRunning()) {
Observer.waitForObserverElectionDelay();
}
}首先创建调用makeObserver方法Observer对象
setObserver(makeObserver(logFactory));
观察者是不参与原子广播协议的对等点。 相反,他们会被领导者告知成功的提案。 因此,观察者自然地充当发布提案流的中继点,并可以减轻追随者的一些连接负载。 观察员可以提交提案,但不投票接受。 有关此功能的讨论,请参阅 ZOOKEEPER-368。
Observer和Follower都继承了Learner
接下来Observer开始连接leader
observer.observeLeader();
https://blog.csdn.net/liereli/article/details/108022874
void observeLeader() throws Exception {
zk.registerJMX(new ObserverBean(this, zk), self.jmxLocalPeerBean);
long connectTime = 0;
boolean completedSync = false;
try {
//设置zab状态,为DISCOVERY
self.setZabState(QuorumPeer.ZabState.DISCOVERY);
// 返回我们认为是领导者的节点的地址。根据当前投票信息
QuorumServer master = findLearnerMaster();
try {
//与 findLearnerMaster 找到的 LearnerMaster 建立连接。 Followers 只连接到 Leaders,Observers 可以连接到任何活跃的 LearnerMaster。 重试直到 initLimit 时间已过或已进行 5 次尝试。
connectToLeader(master.addr, master.hostname);
connectTime = System.currentTimeMillis();
//一旦连接到领导者 ,执行握手协议以建立跟随/观察连接
long newLeaderZxid = registerWithLeader(Leader.OBSERVERINFO);
if (self.isReconfigStateChange()) {
throw new Exception("learned about role change");
}
self.setLeaderAddressAndId(master.addr, master.getId());
self.setZabState(QuorumPeer.ZabState.SYNCHRONIZATION);
//最后,将我们的历史与领导者(如果是跟随者)或学习者主(如果是观察者)同步。集群启动的磁盘数据恢复、leader -> follower数据同步、leader重新选举之后的数据同步
syncWithLeader(newLeaderZxid);
self.setZabState(QuorumPeer.ZabState.BROADCAST);
completedSync = true;
QuorumPacket qp = new QuorumPacket();
while (this.isRunning() && nextLearnerMaster.get() == null) {
//读取数据包
readPacket(qp);
//处理数据包
processPacket(qp);
}
} catch (Exception e) {
LOG.warn("Exception when observing the leader", e);
closeSocket();
// clear pending revalidations
pendingRevalidations.clear();
}
} finally {
currentLearnerMaster = null;
zk.unregisterJMX(this);
if (connectTime != 0) {
long connectionDuration = System.currentTimeMillis() - connectTime;
LOG.info(
"Disconnected from leader (with address: {}). Was connected for {}ms. Sync state: {}",
leaderAddr,
connectionDuration,
completedSync);
messageTracker.dumpToLog(leaderAddr.toString());
}
}
}16.4 FOLLOWING状态逻辑
选主完成following切换到following状态
case FOLLOWING:
try {
LOG.info("FOLLOWING");
//创建follower对象
setFollower(makeFollower(logFactory));
//连接leader
follower.followLeader();
} catch (Exception e) {
LOG.warn("Unexpected exception", e);
} finally {
follower.shutdown();
setFollower(null);
updateServerState();
}
break;followLeader方法
void followLeader() throws InterruptedException {
self.end_fle = Time.currentElapsedTime();
long electionTimeTaken = self.end_fle - self.start_fle;
self.setElectionTimeTaken(electionTimeTaken);
ServerMetrics.getMetrics().ELECTION_TIME.add(electionTimeTaken);
LOG.info("FOLLOWING - LEADER ELECTION TOOK - {} {}", electionTimeTaken, QuorumPeer.FLE_TIME_UNIT);
self.start_fle = 0;
self.end_fle = 0;
fzk.registerJMX(new FollowerBean(this, zk), self.jmxLocalPeerBean);
long connectionTime = 0;
boolean completedSync = false;
try {
self.setZabState(QuorumPeer.ZabState.DISCOVERY);
// 返回我们认为是领导者的节点的地址。根据当前投票信息
QuorumServer leaderServer = findLeader();
try {
//与 findLearnerMaster 找到的 LearnerMaster 建立连接。 Followers 只连接到 Leaders,Observers 可以连接到任何活跃的 LearnerMaster。 重试直到 initLimit 时间已过或已进行 5 次尝试。
connectToLeader(leaderServer.addr, leaderServer.hostname);
connectionTime = System.currentTimeMillis();
long newEpochZxid = registerWithLeader(Leader.FOLLOWERINFO);
if (self.isReconfigStateChange()) {
throw new Exception("learned about role change");
}
//check to see if the leader zxid is lower than ours
//this should never happen but is just a safety check
long newEpoch = ZxidUtils.getEpochFromZxid(newEpochZxid);
if (newEpoch < self.getAcceptedEpoch()) {
LOG.error("Proposed leader epoch "
+ ZxidUtils.zxidToString(newEpochZxid)
+ " is less than our accepted epoch "
+ ZxidUtils.zxidToString(self.getAcceptedEpoch()));
throw new IOException("Error: Epoch of leader is lower");
}
long startTime = Time.currentElapsedTime();
try {
self.setLeaderAddressAndId(leaderServer.addr, leaderServer.getId());
self.setZabState(QuorumPeer.ZabState.SYNCHRONIZATION);
syncWithLeader(newEpochZxid);
self.setZabState(QuorumPeer.ZabState.BROADCAST);
completedSync = true;
} finally {
long syncTime = Time.currentElapsedTime() - startTime;
ServerMetrics.getMetrics().FOLLOWER_SYNC_TIME.add(syncTime);
}
if (self.getObserverMasterPort() > 0) {
LOG.info("Starting ObserverMaster");
om = new ObserverMaster(self, fzk, self.getObserverMasterPort());
om.start();
} else {
om = null;
}
// create a reusable packet to reduce gc impact
QuorumPacket qp = new QuorumPacket();
while (this.isRunning()) {
readPacket(qp);
processPacket(qp);
}
} catch (Exception e) {
LOG.warn("Exception when following the leader", e);
closeSocket();
// clear pending revalidations
pendingRevalidations.clear();
}
} finally {
if (om != null) {
om.stop();
}
zk.unregisterJMX(this);
if (connectionTime != 0) {
long connectionDuration = System.currentTimeMillis() - connectionTime;
LOG.info(
"Disconnected from leader (with address: {}). Was connected for {}ms. Sync state: {}",
leaderAddr,
connectionDuration,
completedSync);
messageTracker.dumpToLog(leaderAddr.toString());
}
}
}16.5 LEADING状态逻辑
case LEADING:
LOG.info("LEADING");
try {
//创建leader对象,leader对象创建时候会监听端口
setLeader(makeLeader(logFactory));
leader.lead();
setLeader(null);
} catch (Exception e) {
LOG.warn("Unexpected exception", e);
} finally {
if (leader != null) {
leader.shutdown("Forcing shutdown");
setLeader(null);
}
updateServerState();
}
break;
}lead方法
void lead() throws IOException, InterruptedException {
self.end_fle = Time.currentElapsedTime();
long electionTimeTaken = self.end_fle - self.start_fle;
self.setElectionTimeTaken(electionTimeTaken);
ServerMetrics.getMetrics().ELECTION_TIME.add(electionTimeTaken);
LOG.info("LEADING - LEADER ELECTION TOOK - {} {}", electionTimeTaken, QuorumPeer.FLE_TIME_UNIT);
self.start_fle = 0;
self.end_fle = 0;
zk.registerJMX(new LeaderBean(this, zk), self.jmxLocalPeerBean);
try {
self.setZabState(QuorumPeer.ZabState.DISCOVERY);
self.tick.set(0);
//加载磁盘中的数据
zk.loadData();
leaderStateSummary = new StateSummary(self.getCurrentEpoch(), zk.getLastProcessedZxid());
// Start thread that waits for connection requests from
// new followers. leader启动服务端口和线程用来接收followers的连接和数据传输
cnxAcceptor = new LearnerCnxAcceptor();
cnxAcceptor.start();
//阻塞等待计算新的 epoch 值,并设置 zxid
long epoch = getEpochToPropose(self.getId(), self.getAcceptedEpoch());
zk.setZxid(ZxidUtils.makeZxid(epoch, 0));
synchronized (this) {
lastProposed = zk.getZxid();
}
newLeaderProposal.packet = new QuorumPacket(NEWLEADER, zk.getZxid(), null, null);
if ((newLeaderProposal.packet.getZxid() & 0xffffffffL) != 0) {
LOG.info("NEWLEADER proposal has Zxid of {}", Long.toHexString(newLeaderProposal.packet.getZxid()));
}
QuorumVerifier lastSeenQV = self.getLastSeenQuorumVerifier();
QuorumVerifier curQV = self.getQuorumVerifier();
if (curQV.getVersion() == 0 && curQV.getVersion() == lastSeenQV.getVersion()) {
try {
LOG.debug(String.format("set lastSeenQuorumVerifier to currentQuorumVerifier (%s)", curQV.toString()));
QuorumVerifier newQV = self.configFromString(curQV.toString());
newQV.setVersion(zk.getZxid());
self.setLastSeenQuorumVerifier(newQV, true);
} catch (Exception e) {
throw new IOException(e);
}
}
newLeaderProposal.addQuorumVerifier(self.getQuorumVerifier());
if (self.getLastSeenQuorumVerifier().getVersion() > self.getQuorumVerifier().getVersion()) {
newLeaderProposal.addQuorumVerifier(self.getLastSeenQuorumVerifier());
}
// We have to get at least a majority of servers in sync with
// us. We do this by waiting for the NEWLEADER packet to get
// acknowledged
//阻塞等待接收过半的 follower 节点发送的 ACKEPOCH 信息; 此时说明已经确定了本轮选举后 epoch 值
waitForEpochAck(self.getId(), leaderStateSummary);
self.setCurrentEpoch(epoch);
self.setLeaderAddressAndId(self.getQuorumAddress(), self.getId());
self.setZabState(QuorumPeer.ZabState.SYNCHRONIZATION);
try {
// 阻塞等待 超过半数的节点 follower 发送了 NEWLEADER ACK 信息;此时说明过半的 follower 节点已经完成数据同步
waitForNewLeaderAck(self.getId(), zk.getZxid());
} catch (InterruptedException e) {
shutdown("Waiting for a quorum of followers, only synced with sids: [ "
+ newLeaderProposal.ackSetsToString()
+ " ]");
HashSet<Long> followerSet = new HashSet<Long>();
for (LearnerHandler f : getLearners()) {
if (self.getQuorumVerifier().getVotingMembers().containsKey(f.getSid())) {
followerSet.add(f.getSid());
}
}
boolean initTicksShouldBeIncreased = true;
for (Proposal.QuorumVerifierAcksetPair qvAckset : newLeaderProposal.qvAcksetPairs) {
if (!qvAckset.getQuorumVerifier().containsQuorum(followerSet)) {
initTicksShouldBeIncreased = false;
break;
}
}
if (initTicksShouldBeIncreased) {
LOG.warn("Enough followers present. Perhaps the initTicks need to be increased.");
}
return;
}
//启动 zk server,此时集群可以对外正式提供服务
startZkServer();
String initialZxid = System.getProperty("zookeeper.testingonly.initialZxid");
if (initialZxid != null) {
long zxid = Long.parseLong(initialZxid);
zk.setZxid((zk.getZxid() & 0xffffffff00000000L) | zxid);
}
if (!System.getProperty("zookeeper.leaderServes", "yes").equals("no")) {
self.setZooKeeperServer(zk);
}
self.setZabState(QuorumPeer.ZabState.BROADCAST);
self.adminServer.setZooKeeperServer(zk);
// We ping twice a tick, so we only update the tick every other
// iteration
boolean tickSkip = true;
// If not null then shutdown this leader
String shutdownMessage = null;
while (true) {
synchronized (this) {
long start = Time.currentElapsedTime();
long cur = start;
long end = start + self.tickTime / 2;
while (cur < end) {
wait(end - cur);
cur = Time.currentElapsedTime();
}
if (!tickSkip) {
self.tick.incrementAndGet();
}
// We use an instance of SyncedLearnerTracker to
// track synced learners to make sure we still have a
// quorum of current (and potentially next pending) view.
SyncedLearnerTracker syncedAckSet = new SyncedLearnerTracker();
syncedAckSet.addQuorumVerifier(self.getQuorumVerifier());
if (self.getLastSeenQuorumVerifier() != null
&& self.getLastSeenQuorumVerifier().getVersion() > self.getQuorumVerifier().getVersion()) {
syncedAckSet.addQuorumVerifier(self.getLastSeenQuorumVerifier());
}
syncedAckSet.addAck(self.getId());
for (LearnerHandler f : getLearners()) {
if (f.synced()) {
syncedAckSet.addAck(f.getSid());
}
}
// check leader running status
if (!this.isRunning()) {
// set shutdown flag
shutdownMessage = "Unexpected internal error";
break;
}
if (!tickSkip && !syncedAckSet.hasAllQuorums()) {
// Lost quorum of last committed and/or last proposed
// config, set shutdown flag
shutdownMessage = "Not sufficient followers synced, only synced with sids: [ "
+ syncedAckSet.ackSetsToString()
+ " ]";
break;
}
tickSkip = !tickSkip;
}
for (LearnerHandler f : getLearners()) {
f.ping();
}
}
if (shutdownMessage != null) {
shutdown(shutdownMessage);
// leader goes in looking state
}
} finally {
zk.unregisterJMX(this);
}
}查看更多原文,技术咨询与支持,可以扫描微信公众号进行回复咨询
Zookeeper16, Zookeeper安装配置14, Zookeeper源码解析16